Authors
Vincent Chen, Paroma Varma, Ranjay Krishna, Michael Bernstein, Christopher Re, Li Fei-Fei
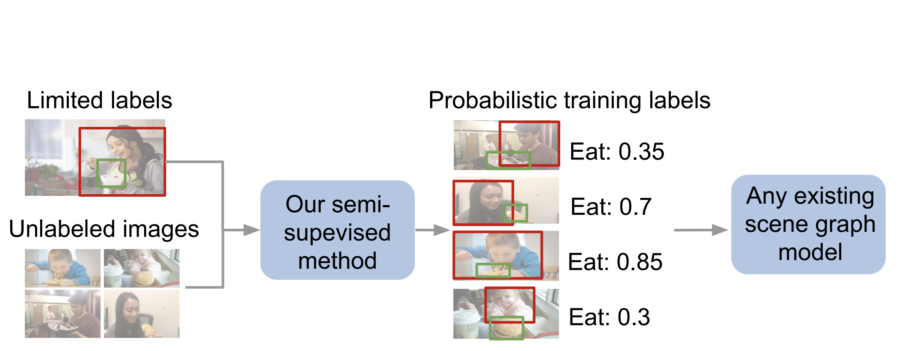
Image: Our semi-supervised method automatically generates probabilistic relationship labels to train any scene graph model.
Abstract
Visual knowledge bases such as Visual Genome power numerous applications in computer vision, like visual question answering and captioning, but suffer from sparse, incomplete relationships. All scene graph models to date are limited to training on a small set of visual relationships that have thousands of training labels each. Hiring humans annotators is expensive, and using textual knowledge base completion methods are incompatible with visual data. In this paper, we introduce a semi-supervised method that assigns probabilistic relationship labels to a large number of unlabeled images from a few labeled examples. We analyze visual relationships and suggest two types of image-agnostic features that are used to generate noisy heuristics, whose outputs are aggregated together using a factor graph-based generative model. With as few as 10 labeled examples of a relationship, the generative model creates enough training data to train any existing state-of-the-art scene graph model. We demonstrate that our method for generating training data outperforms other baseline approaches including a transfer learning approach pretrained on a different set of relationships by 8.27 recall@100 points. We further analyze visual relationships and define a complexity metric that serves as an indicator (R^2 = 0.787) for conditions under which our method succeeds over transfer learning, the de-facto approach for training with limited labeled examples.
The research was published in IEEE International Conference on Computer Vision on 10/31/2019. The research is supported by the Brown Institute Magic Grant for the project Learning to Engage in Conversations with AI Systems.
Access the paper: https://arxiv.org/pdf/1904.11622.pdf
To contact the authors, please send a message to ranjaykrishna@cs.stanford.edu