
The Brown Institute, a collaboration between Columbia Journalism School and Stanford Engineering, awards annual “Magic Grants” to projects from both campuses that blend journalistic insight with technical innovation. This year
News

2026 Summer Entrepreneurship Program Kicks Off
This week, we kicked off our annual summer entrepreneurship program. For the last 4 years, the Brown Institute has been running a program led by Justin Hendrix, CEO of Tech

Reflecting on Media Party 2026
May 8th through 10th were lively at the Brown Institute. Journalists, developers, students, researchers, and media professionals filled Pulitzer Hall, moving between workshops, keynotes, lunches, and lightning talks. It was
Happening this Weekend – Media Party NYC!
From Friday – Sunday, May 8 to 10, the Brown Institute hosts Media Party NYC 2026, bringing together journalists, technologists, researchers, and entrepreneurs from around the world to take on
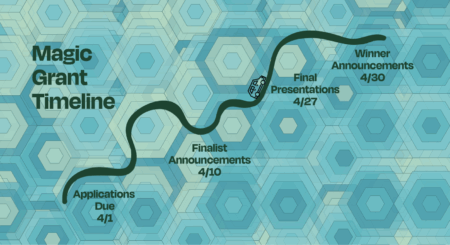
Magic Grant Season is Underway
It’s Magic Grant Season at the Brown Institute, and for the past two weeks, we’ve done a lot of reading. Every year, the Brown Institute receives proposals from Columbia, Stanford,

Meet the 2026 Venture Challenge Winners
What this year’s cohort told us about what media needs now Over the past two weeks, The Brown Institute partnered with StartUp Columbia to host our annual Venture Challenge (Media

Brown Institute team launches SFAI Agency and Croquis tool
The Brown Institute is excited to share news from our 2025-2026 bicoastal Magic Grant Croquis. The team launched recently launched a new tool as well as their official organization, the

Welcome Tanya Chawla, Our New Program Manager
We’re thrilled to announce that Tanya Chawla has joined the Brown Institute at Columbia Journalism School as our new Program Manager. The Program Manager role sits at the heart of

What the Kids Already Know
In December, the Brown Institute for Media Innovation convened a summit in New York with Hearst and OpenAI that brought together some of the most senior people in journalism and