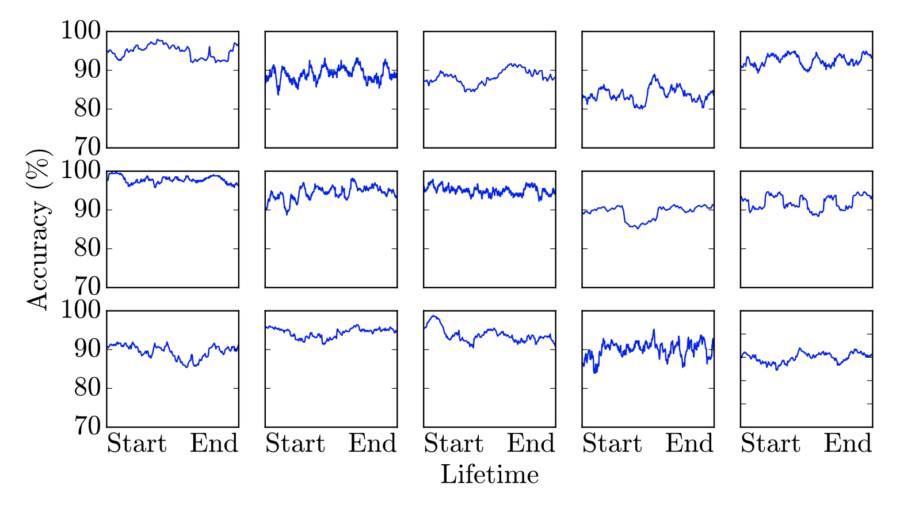
A selection of individual workers’ accuracy over time during the question answering task. Each worker remains relatively constant throughout his or her entire lifetime.
Authors
Kenji Hata, Ranjay Krishna, Li Fei-Fei, Michael Bernstein
Abstract
Microtask crowdsourcing is increasingly critical to the creation of extremely large datasets. As a result, crowd workers spend weeks or months repeating the exact same tasks — making it necessary to understand their behavior over these long periods of time. We utilize three large, longitudinal datasets of nine million annotations collected from Amazon Mechanical Turk to examine claims that workers fatigue or satisfice over these long periods, producing lower quality work. We find that, contrary to these claims, workers are extremely stable in their accuracy over the entire period. To understand whether workers set their accuracy based on the task’s requirements for acceptance, we then perform an experiment where we vary the required accuracy for a large crowdsourcing task. Workers did not adjust their accuracy based on the acceptance threshold: workers who were above the threshold continued working at their usual quality level, and workers below the threshold self-selected themselves out of the task. Capitalizing on this consistency, we demonstrate that it is possible to predict workers’ long-term accuracy using just a glimpse of their performance on the first five tasks.
The research was published in ACM Conference on Computer-Supported Cooperative Work and Social Computing on 11/2/2017. The research is supported by the Brown Institute Magic Grant for the project Visual Genome.
Access the paper: http://cs.stanford.edu/people/ranjaykrishna/glimpse/glimpse.pdf
To contact the authors, please send a message to ranjaykrishna@cs.stanford.edu