By Alex Calderwood.
You’re browsing Instagram and you see someone wearing a winter coat that speaks to you. You comment on the post and ask “Love the jacket, what kind is it?.” A few minutes later, the poster responds “Canada Goose, obviously.” You remember something about the brand and other designer clothes being banned from some British schools to stop ‘poverty shaming.’ Best for you to move on.
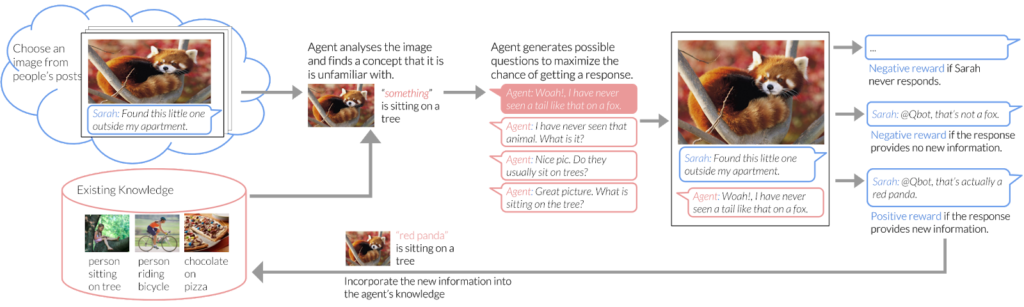
For two humans, this is an easy exchange of information. But try casting a data-seeking computer in your role, and it will face a series of difficult challenges. For a computer, the process begins by discerning there is a jacket in the image and, being introspective enough to realize that of its qualities, knowledge of the type and brand of jacket is valuable. From there, the tasks only become more difficult — formulating a question to get at this information, asking it in a way that is likely to get a response from the Instagram poster, and then interpreting their answer. Thanks to Apoorva Dornadula and Ranjay Krishna’s team at Stanford, led by Professor Michael Bernstein and funded in part by a 2018-19 Magic Grant, developing and applying this information gathering workflow is becoming a reality.
The machine learning models underlying artificial intelligence systems are only as good as the data that they’re built and trained on. The project, Learning to Engage in Conversations with AI Systems, seeks to advance the development of artificial intelligence by changing the way we collect and build these datasets. By focusing on the learning of social norms and engagement strategies that allow an AI system to retrieve information through question asking, a computer is able to build learning datasets of its own, soliciting much needed user feedback. Among the goals of the project, says Krishna, is the ability to treat people less as a source of data to be studied, but rather as partners that actively teach the systems using natural language, posing and interpreting questions.
They call the process “engagement learning.” To illustrate their approach, Dornadula, Krishna and their collaborators built ELIA (Engagement Learning Interaction Agent), which uses “deep reinforcement learning” to interpret images on Instagram and generates intelligible questions that are likely to be answered. The results include both valuable insights about how to generate meaningful and provocative questions, as well as the learning of new visual concepts. Details and findings from their work can be found in the ACM UIST 2018 Adjunct Proceedings.
Currently, their ELIA Instagram bot engages with about 800-1000 people per day and has asked over 400,000 questions. With this information, the models built by the team can understand objects such as uniquely branded jackets with as little as five to ten answered questions. They do this by bootstrapping their data with other knowledge sources, such as the Visual Genome database — a 2014-16 Magic Grant — in a process they’ve termed “few-shot learning”. For the remainder of their current grant, the team will be working to improve engagement rates with users around the questions posed by ELIA, as well as to improve various vision tasks.
The new AI agents they anticipate will be intelligent enough to understand where their knowledge is lacking and be able to ask a human for help. They will use a graphical representation of knowledge the team is pursuing known as a ‘Scene Graph’, which represents knowledge as a network, and can easily be built from natural language and images. Eventually, from the results of this team’s work, machine learning systems will no longer rely on static datasets to identify what’s in an image, but will instead continuously learn by generating their own data in conjunction with humans. This work could close the loop left open by machines’ previous inability to ask someone for help when they don’t know something, and make interacting with computers more engaging and natural.