
The David and Helen Gurley Brown Institute for Media Innovation is proud to announce the 2024-2025 Magic Grant Call for Proposals. Each year, the Brown Institute awards close to $1M

The Winners of our Venture Challenge!
For the third consecutive year, the Brown Institute partnered with Columbia Entrepreneurship to offer a segment of the StartupColumbia Venture Challenge dedicated to media initiatives. The first round of our competition

(+1) Sterling Proffer joins our Entrepreneurs in Residence
The Brown Institute has recruited an impressive list of Entrepreneurs in Residence including Diane Chang, Ethar El-Katatney, Jennifer 8. Lee and Shazna Nessa. To the ranks we are pleased to
Round 1 of the 2024 Startup Columbia Venture Challenge
For the third consecutive year, the Brown Institute partnered with Columbia Entrepreneurship to offer a segment of the Startup Columbia Venture Challenge dedicated to media initiatives. The first round of
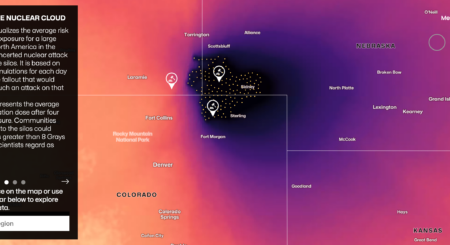
Brown Institute collaboration makes Sigma Awards 2024 shortlist!
The Missiles on Our Land, is a story of risk, mixing new scientific research, in-depth interviews and striking data visualizations — a collaboration by groups from Princeton University, Columbia Journalism

Join us for an Open Source AI Hackathon
Catalyzing New Forms of Journalism and Civic Information Join Hacks/Hackers and the Brown Institute for Media Innovation at Columbia University for a weekend of building with open source AI for

“Reaching for Air” goes live!
The Salt Lake Tribune, in collaboration with KUER, has launched an innovative interactive series titled “Reaching for Air”, accessible at reachingforair.sltrib.com. This three-part series, the work of journalists Saige Miller

Announcing the 2024 Startup Columbia Venture Challenge
The submissions for the 2024 Startup Columbia Venture Challenge are due February 9th! For the past three years, Brown has sponsored a “Media Track” for this competition. It is designed
Wikimedia NYC and Brown bring you a Wikipedia Day celebration!
Wikipedia Day! January 14, 2024. Here’s the program for the day. Drop in virtually for events in the Lecture Hall and the World Room. On January 14, 2024, join Wikimedia